- Published on
NVIDIA CPX GPU,专门针对推理Prefill与Decode两阶段计算范式优化的硬件
- Authors
- Name
- Mao
Transformer推理Prefill与Decode两阶段计算范式
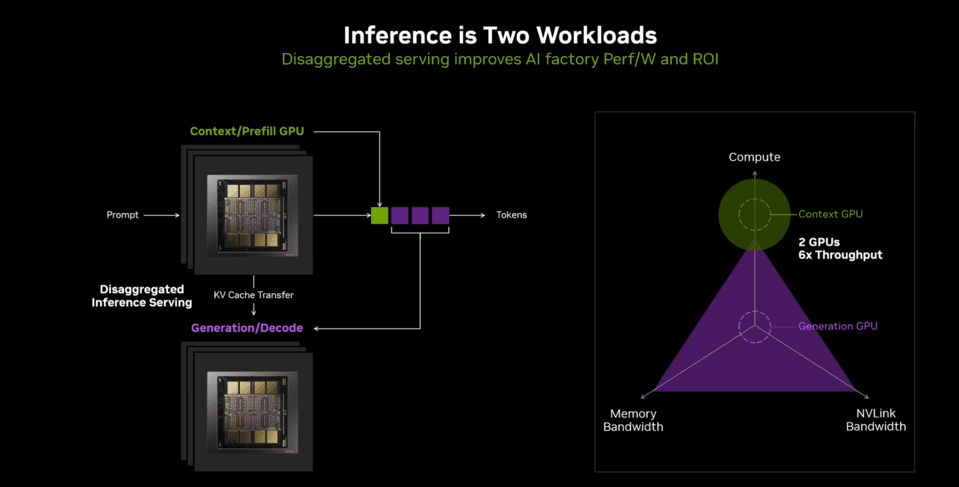
Transformer推理分为计算密集型的Prefill(上下文)阶段和内存带宽敏感型的Decode(生成)阶段,对基础设施需求截然不同。
一方面,Prefill阶段依赖高算力处理长上下文输入;另一方面,Decode阶段需大带宽支持逐Token生成。
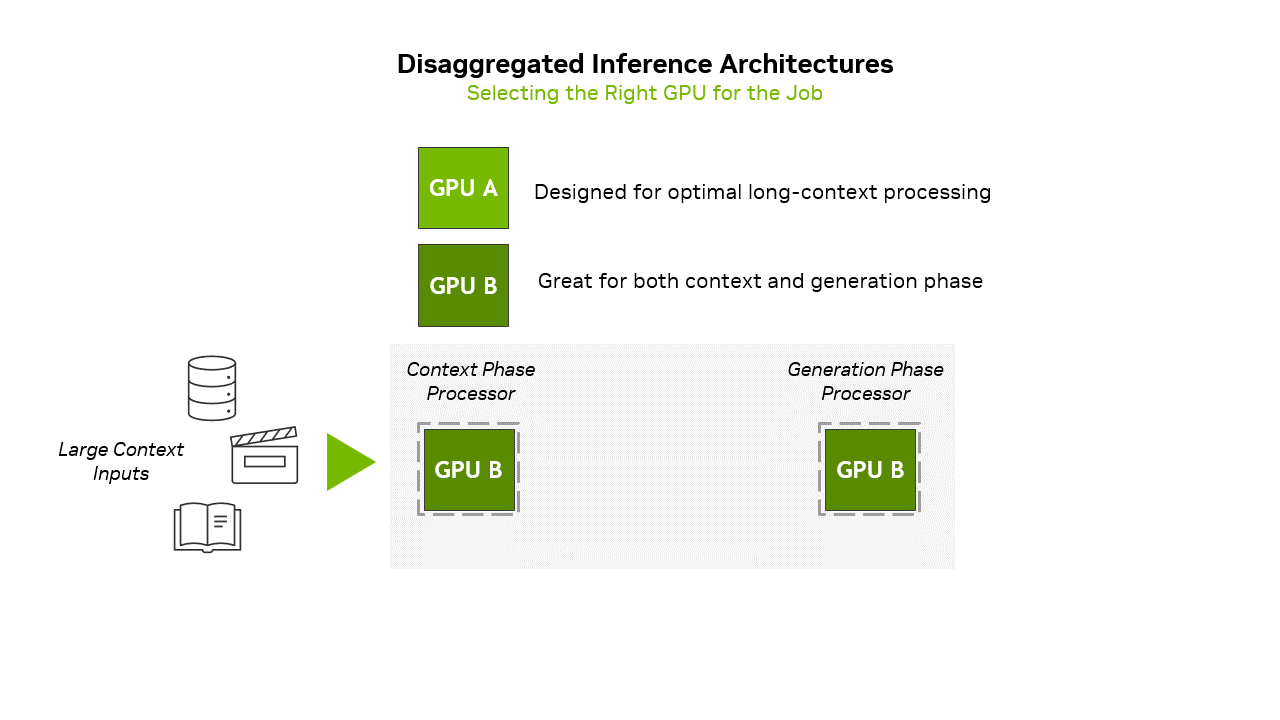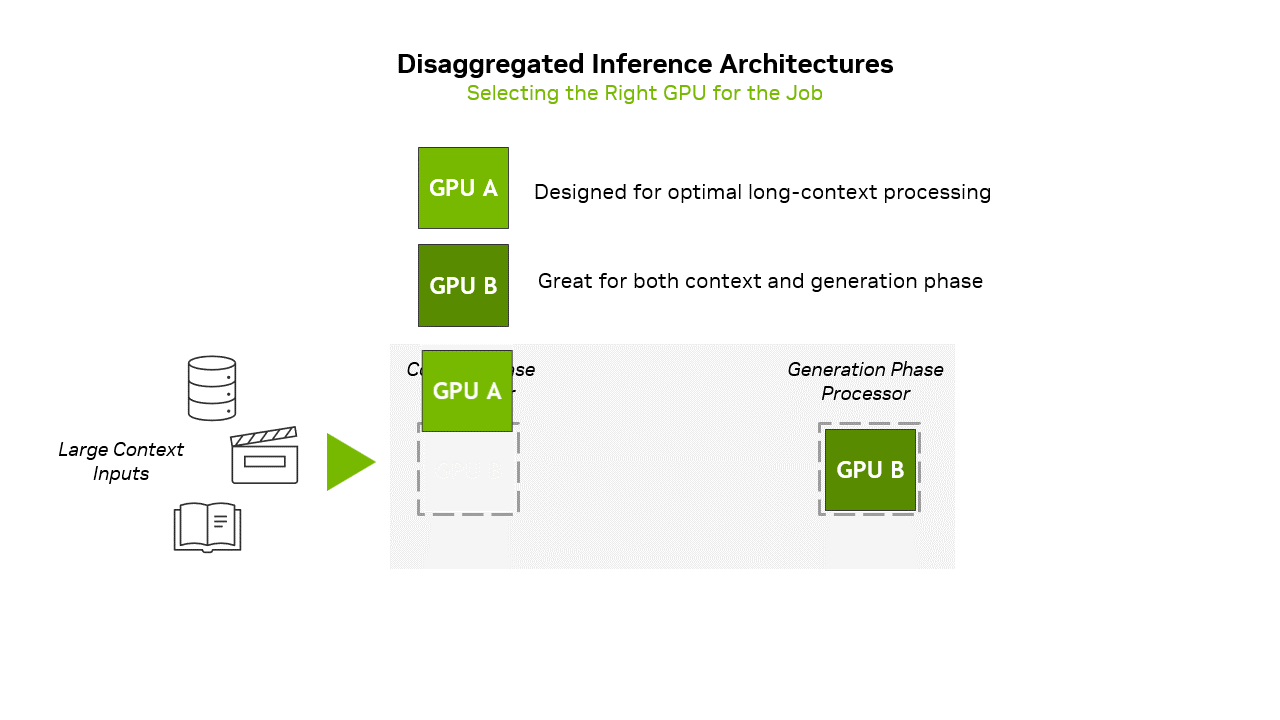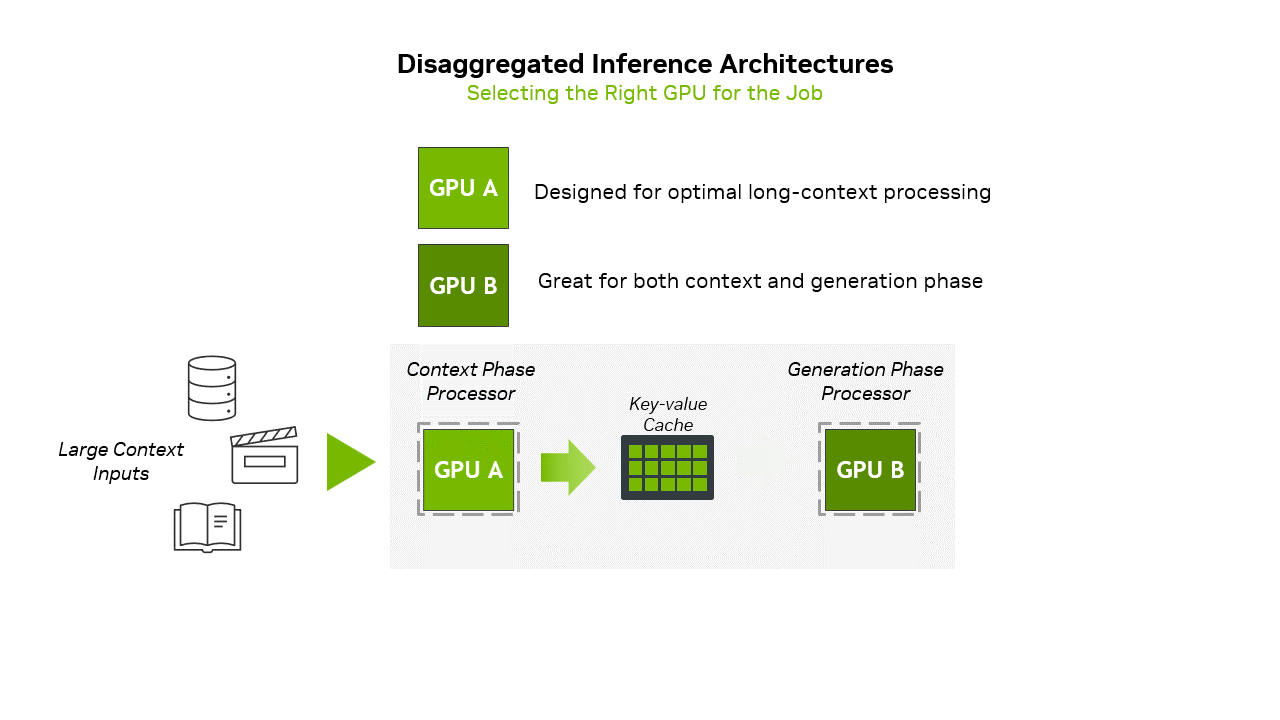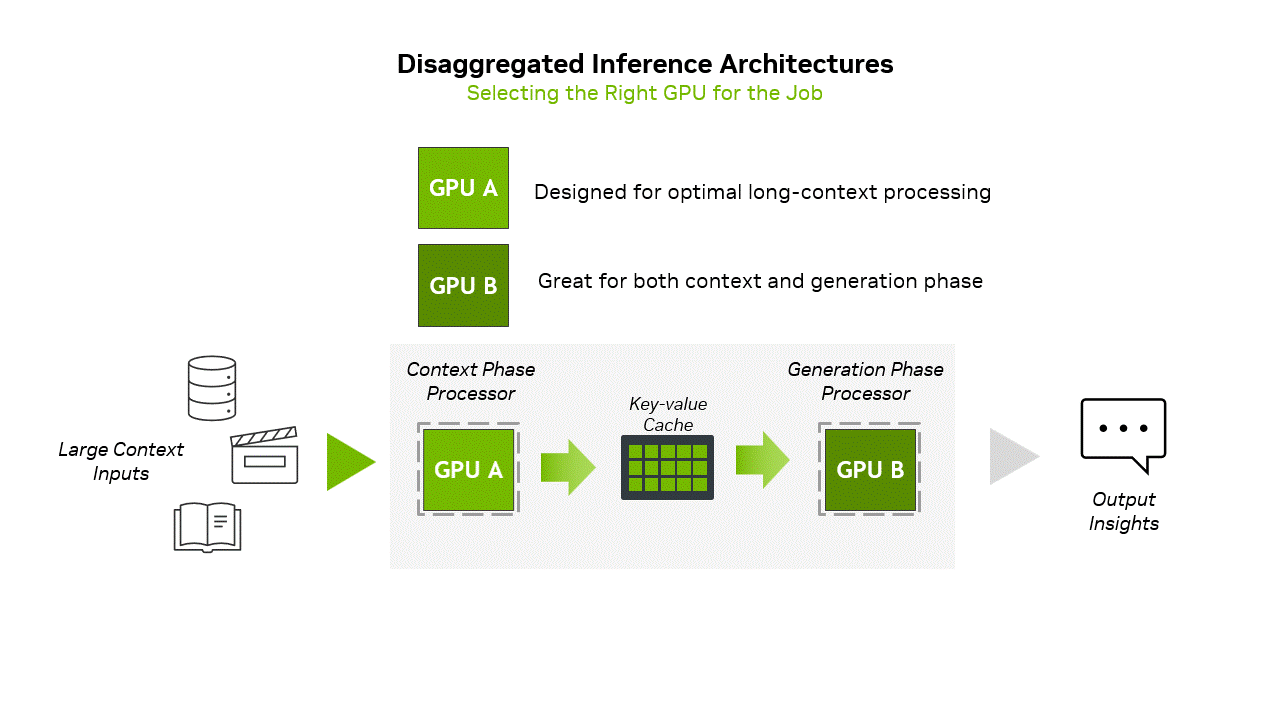
针对这一模式,英伟达推出专为Prefill优化的Rubin CPX GPU与Decode阶段专用Rubin GPU组成的解耦架构,通过NVLink互联传递KV Cache,NVIDIA Dynamo软件协调KV缓存传输、LLM感知路由和内存管理,解决解耦架构复杂度,该方案在MLPerf测试中创下性能纪录,显著降低推理成本并拓展AI应用边界。
Transformer推理模式:Prefill阶段是计算密集型任务需要强算力,Decode 阶段是内存消耗型任务且时延敏感、需要大带宽。
Inference consists of two distinct phases: the context phase and the generation phase, each placing fundamentally different demands on infrastructure. The context phase is compute-bound, requiring high-throughput processing to ingest and analyze large volumes of input data to produce the first token output result. In contrast, the generation phase is memory bandwidth-bound, relying on fast memory transfers and high-speed interconnects, such as NVLink, to sustain token-by-token output performance.图片
NVIDIA CPX GPU,专门针对推理Prefill与Decode两阶段计算范式优化的硬件
针对上述模式,推出 Rubin CPX GPU(上图中,GPU A为 Rubin CPX GPU),针对Prefill阶段长上下文专门优化

机柜方案
Vera Rubin NVL144 CPX 平台,相比较 NVIDIA GB300 NVL72,3倍 attention acceleration加速
Vera Rubin NVL144 CPX机柜配置
Rubin CPX works in tandem with NVIDIA Vera CPUs and Rubin GPUs for generation-phase processing, forming a complete, high-performance disaggregated serving solution for long-context use cases. The NVIDIA Vera Rubin NVL144 CPX rack integrates 144 Rubin CPX GPUs, 144 Rubin GPUs, and 36 Vera CPUs to deliver 8 exaFLOPs of NVFP4 compute—7.5× more than the GB300 NVL72—alongside 100 TB of high-speed memory and 1.7 PB/s of memory bandwidth, all within a single rack.


NVL 144 CPX互联,使用NVLink(推测)
Using NVIDIA Quantum-X800 InfiniBand or Spectrum-X Ethernet, paired with NVIDIA ConnectX-9 SuperNICs and orchestrated by the Dynamo platform, the Vera Rubin NVL144 CPX is built to power the next wave of million-token context AI inference workloads—cutting inference costs and unlocking advanced capabilities for developers and creators worldwide.
通过 Nvidia Dynamo软件协同推理流程,消除disaggregated architecture引入的复杂度
However, disaggregation introduces new layers of complexity, requiring precise coordination across low-latency KV cache transfers, LLM-aware routing, and efficient memory management. NVIDIA Dynamo serves as the orchestration layer for these components, and its capabilities played a pivotal role in the latest MLPerf Inference results. Learn how disaggregation with Dynamo on GB200 NVL72 set new performance records.
关键点:
解耦架构(disaggregated architecture)
专门针对Transformer Attention 推理模式:Rubin CPX GPU负责Prefill阶段计算,Rubin GPU负责Decode阶段计算
互联:使用NVLink连接Rubin CPX GPU与Rubin GPU,传递KVCache
流程协同:通过 Nvidia Dynamo软件协同推理流程,消除disaggregated architecture引入的复杂度
RoadMap
Rubin CPX 会在 2026 年底推出,之后会和 Rubin GPU、Vera CPU 组成异构生态

参考资料
- 原文:NVIDIA Rubin CPX Accelerates Inference Performance and Efficiency for 1M+ Token Context Workloads:https://developer.nvidia.com/blog/nvidia-rubin-cpx-accelerates-inference-performance-and-efficiency-for-1m-token-context-workloads/
- 英伟达推出新一代GPU Rubin CPX:https://www.eet-china.com/mp/a438020.html